文章信息:
Wang, B., Zhang, J., Zhang, R., Li, Y., Li, L., & Nakashima, Y. (2024). Improving facade parsing with vision transformers and line integration. Advanced Engineering Informatics, 60, 102463.
下载链接:
https://www.sciencedirect.com/science/article/pii/S1474034624001113
论文摘要:
立面解析是一项关键的计算机视觉任务,在建筑、城市规划和能源效率等领域具有深远的应用。 尽管基于深度学习的方法最近在某些开源数据集上取得了令人印象深刻的结果,但它们在实际应用中的可行性仍然不确定。 现实世界的场景要复杂得多,需要更高的计算效率。 现有的数据集通常不足以表示这些设置,并且以前的方法经常依赖额外的检测模型来提高准确性,这需要大量的计算成本。 在本文中,我们首先介绍综合外观解析(CFP),这是一个精心设计的数据集,旨在涵盖现实世界中复杂的外观解析任务。 该数据集总共包含 602 张高分辨率街景图像,捕捉了各种具有挑战性的场景,包括倾斜角度和密集聚集的建筑物,并为每张图像精心设计了注释。 此外,还提出了一种新的方法,称为基于修订的 Transformer Facade Parsing (RTFP)。 这标志着ViT在立面解析中的开创性应用,我们的实验结果明确证实了它的优点。 我们还设计了线采集、过滤和修正(LAFR),这是一种高效而准确的修正算法,可以仅使用立面的先验知识通过简单的线检测来改进分段结果。 在ECP 2011、RueMonge 2014和我们的CFP中,实验结果验证了我们方法的优越性。
研究框架:

图1:来自 (a) RueMonge 2014 和 (b) CFP 数据集的图像样本
结果:
我们的研究得出了以下几个关键结论:
兼容性:LAFR算法与各种模型架构兼容性强,在超出Segmenter范畴的其他模型上均表现出显著性能提升,尤其是对PSPNet和Deeplabv3+模型。然而,将LAFR应用于UNet和FCN模型则导致性能下降,这强调了利用先进的分割模型实现最佳性能的重要性。
预训练:我们的研究突出了预训练模型对立面分割任务的影响。MAE-based预训练在所有三个数据集上始终优于其他方法。在ImageNet上预训练的模型落后,而随机初始化的模型产生了较差的结果。这些发现强调了MAE-based预训练在提升立面分割任务中模型性能方面的有效性。
ViT结构:ViT模型的配置对我们的RTFP系统的性能有重大影响。对不同模型大小和补丁大小进行实验表明,增加ViT模型的大小和减小补丁大小均对预测准确性产生积极影响。然而,较大的ViT模型会带来巨大的计算需求。因此,我们建议使用带有大小为16的“Base”ViT模型,在预测性能和计算效率之间达到实际平衡,成为RTFP系统的最佳选择。
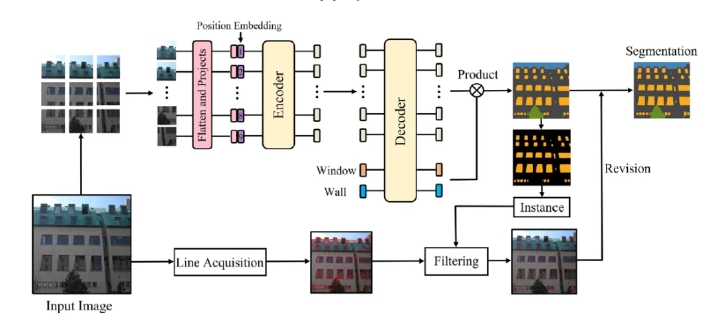
图2:基于 Rvision 的转换器外观解析(RTFP)的流程
讨论和结论:
CFP数据集的发布为评估立面解析技术在真实世界场景中的性能提供了一个测试场。RTFP方法通过更好地理解上下文信息和利用MAE预训练,显著优于先前的工作。LAFR修正方法通过仅依赖基本的线条检测和预定义的细化标准,避免了使用重型检测模型的需求,实现了最先进的性能。这些方法的提出为立面解析任务提供了一个强大的工具,具有在真实世界场景中部署的潜力。