文章信息
从城市数字孪生中自动生成合成数据集用于建筑外墙的实例分割
Jiaxin Zhang, Tomohiro Fukuda, Nobuyoshi Yabuki, Automatic generation of synthetic datasets from a city digital twin for use in the instance segmentation of building facades, Journal of Computational Design and Engineering, 2022;, qwac086, https://doi.org/10.1093/jcde/qwac086
Youtube
https://www.youtube.com/watch?v=WnN9zj3WwjA
Generating synthetic datasets from a city digital twin (从城市数字双胞胎中生成合成数据集)
论文摘要
建筑物立面数据的提取和整合对于城市环境的信息基础设施的发展是必要的。然而,现有的基于语义分割的建筑外墙解析方法在区分相连建筑的单个实例方面存在困难。人工收集和注释大型数据集中的建筑外墙实例既费时又费力。随着最近城市数字双胞胎(CDTs)的发展和使用,大量高质量的建筑数字资产已经被创建。这些资产使得生成高质量和高性价比的合成数据集成为可能,这些数据集可以取代真实世界的数据集,作为基于监督学习的建筑外墙实例分割的训练集。在这项研究中,我们开发了一个新的框架,可以从CDT中自动产生合成数据集。通过在游戏引擎中渲染城市数字资产,建立了一个合成街景的自动生成系统,同时该系统自动生成了建筑外墙的实例注释。混合数据集HSRBFIA,以及包含不同比例的合成和真实数据的各种子集,被用来训练用于外墙实例分割的深度学习模型。在我们的实验中,比较了两种类型的合成数据(基于CDT和基于虚拟),结果显示,与虚拟合成数据(没有真实世界的对应物)相比,CDT合成数据在促进真实世界图像的深度学习训练方面更为有效。通过将真实数据的某一部分与提议的CDT合成图像互换,性能几乎可以与使用真实世界训练集时达到的效果相匹配。
Abstract
The extraction and integration of building facade data are necessary for the development of information infrastructure for urban environments. However, existing methods for parsing building facades based on semantic segmentation have difficulties in distinguishing individual instances of connected buildings. Manually collecting and annotating instances of building facades in large datasets is time-consuming and labor-intensive. With the recent development and use of city digital twins (CDTs), massive high-quality digital assets of buildings have been created. These assets make it possible to generate high-quality and cost-effective synthetic datasets that can replace real-world ones as training sets for the supervised learning-based instance segmentation of building facades. In this study, we developed a novel framework that can automatically produce synthetic datasets from a CDT. An auto-generation system for synthetic street views was built by rendering city digital assets in a game engine, while the system auto-generated the instance annotations for building facades. The hybrid dataset HSRBFIA, along with various subsets containing different proportions of synthetic and real data, were used to train deep learning models for facade instance segmentation. In our experiments, two types of synthetic data (CDT-based and virtual-based) were compared, and the results showed that the CDT synthetic data were more effective in boosting deep learning training with real-world images compared with the virtual synthetic data (no real-world counterparts). By swapping a certain portion of the real data with the proposed CDT synthetic images, the performance could almost match what is achievable when using the real-world training set.
文章下载链接
https://academic.oup.com/jcde/advance-article/doi/10.1093/jcde/qwac086/6677399
研究框架
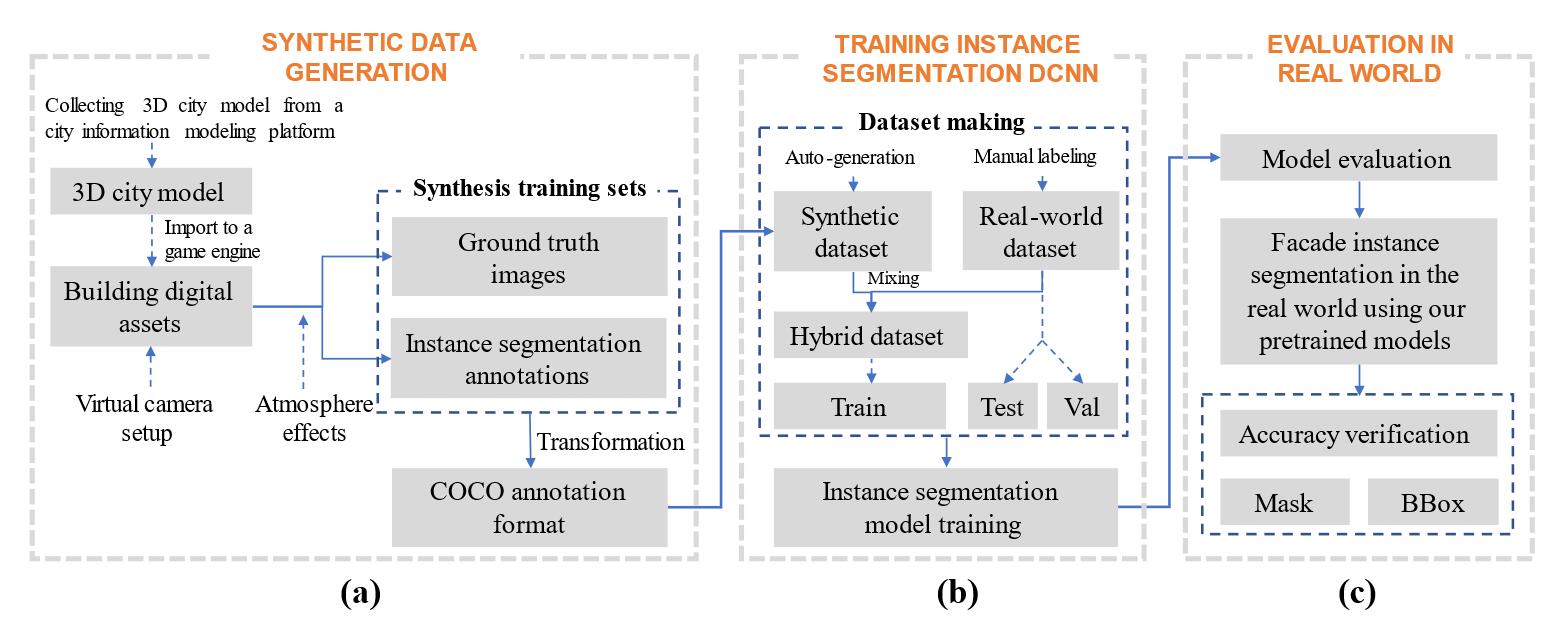
我们研究的工作流程:(a)合成数据生成过程,(b)训练基于DCNN的实例分割,以及(c)使用真实世界图像进行评估。
研究高光
利用城市数字孪生模型(CDT)自动生成带有实例注释的合成外墙图像。
CDT合成数据在改善建筑外墙的实例分割结果方面比虚拟合成数据更好。
通过增加提出的CDT合成数据,可以提高实例分割的性能。
提出的自动系统可以大大降低数据集的制作成本。
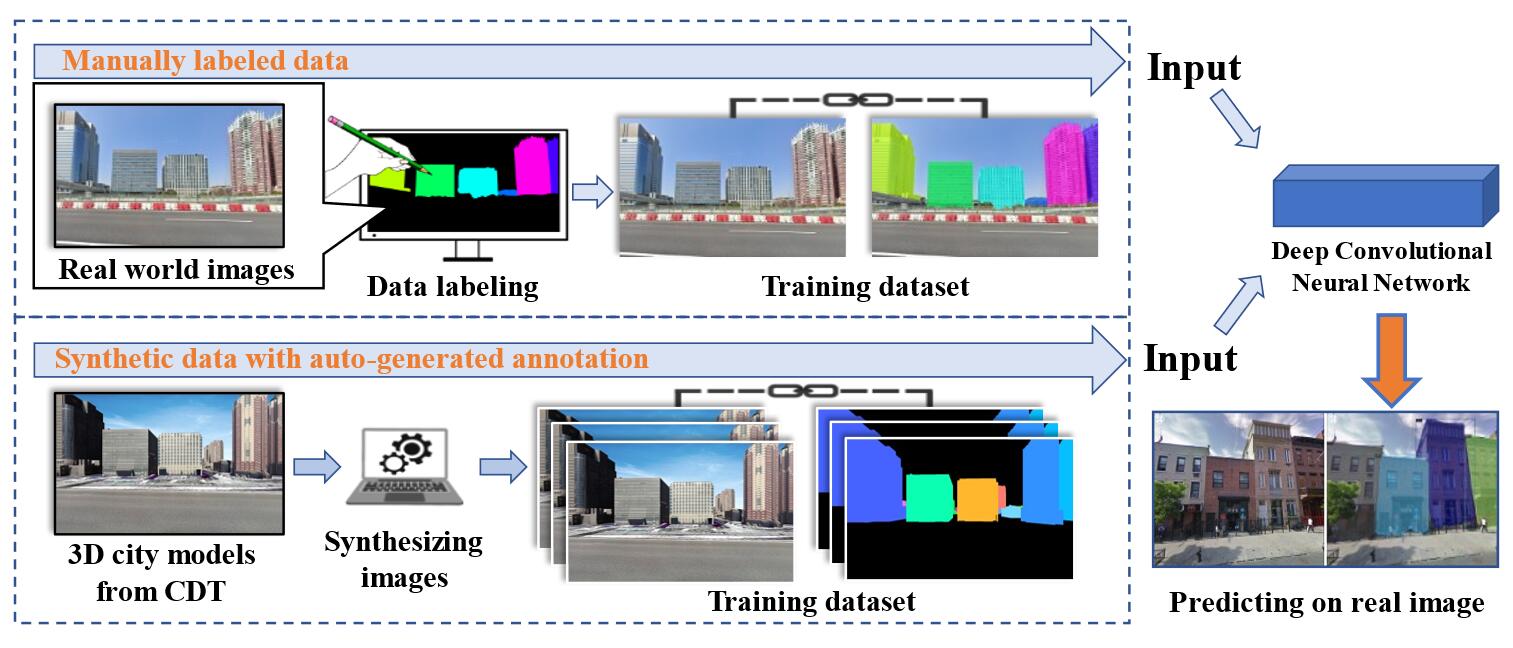
手工注释的数据集和自动生成的合成数据集的比较。传统的方法在制作训练集时需要对图像进行手工标注,而我们提出的系统可以通过使用CDT的数字资产自动创建带有实例标注的合成数据。
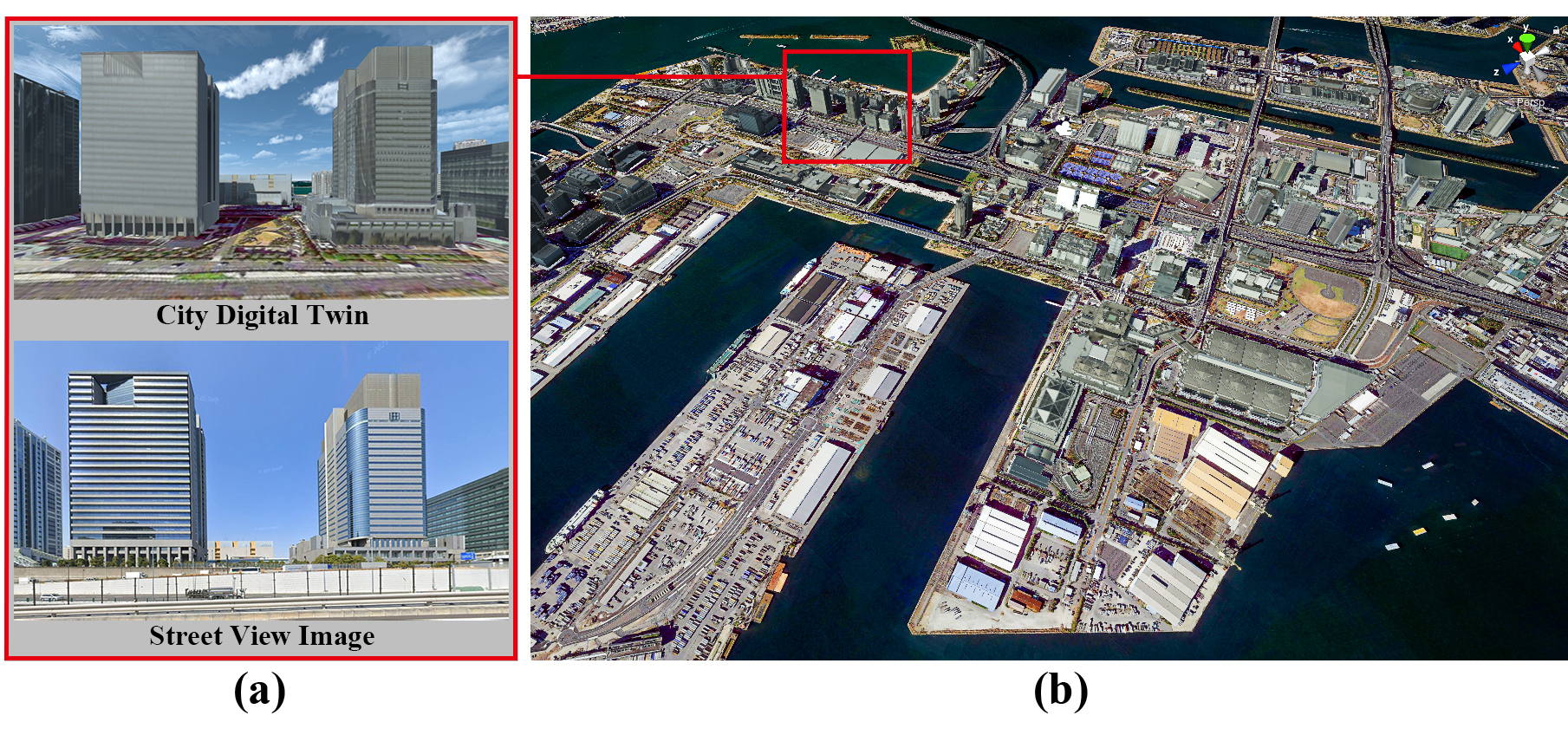
我们研究区域的三维城市模型。(a) CDT的例子与现实世界的街景对应(Wangan-doro大道,东京;2021年3月;纬度。35.6283,经度:139.7782)。(b) 城市数字孪生城市的鸟瞰图。

以前的研究表明,当只使用合成数据集作为CNN的训练集时,真实街道场景的分割精度并不令人满意。本研究引入了一个混合数据集,我们称之为合成和真实世界建筑立面图像和注释的混合集合(HSRBFIA),通过在训练阶段同时学习合成和真实领域来解决这个问题。图3显示了使用不同比例的真实和合成数据混合进行外墙分割的定性结果。我们用一个红色的虚线矩形来突出街景图像中容易在外墙实例分割过程中失败的部分,比如远离摄像头的建筑和那些具有复杂外墙构成的建筑。我们观察到,使用CDT生成的合成数据训练系统足以识别低层建筑、高层建筑和综合建筑。真实和合成数据的组合(HSRBFIA-60)对非建筑项目、小型建筑,甚至是复杂的外墙产生了高度精确的结果。
本研究成果的意义
本研究的贡献可归纳为以下几点。
传统的标记数据的方法依赖于手工劳动。我们的研究试图用一个自动生成系统来替代人工标注过程,以创建CDT合成数据来训练DCNN。我们的方法所花费的时间大约是人工标注每张图片的1/2,050,这可以大大降低标注数据所需的成本。
通过比较真实、合成和混合数据集的DCNN训练结果,我们证明了用提议的合成数据扩展训练集可以提高真实图片上外墙实例分割的准确性。我们还提出了一个基线策略,表明在相同的LOD和渲染设置下,使用CDT合成数据的增强效果优于使用虚拟合成数据的增强效果。具体来说,当一定比例的真实数据被加载到CDT合成数据集中时,分割的准确性得到了显著的提升,以至于其性能可以与使用100%真实数据时的性能相竞争。这表明我们提出的合成数据集有可能取代训练集中的真实图像。
对其他多个城市的验证表明了我们提出的框架的可转移性。我们的数据集可以为大多数现代建筑风格获得有希望的预测结果。然而,对于具有特色建筑风格或高密度街道的环境,分割的准确性需要改进。
我们的方法生成了基于CDT的合成数据集,有效地利用了城市信息建模和数字资产。随着CDT的进一步发展和完善,该研究框架可以应用于城市环境中的其他元素,这将使它们在数字基础设施的进一步发展中丰富其语义信息。

数字城市与人居环境实验室
▲感谢关注